Fine-grained GEMM & Communication Overlap
Fine-grained GEMM & Communication Overlap#


Algorithms#
For GEMM + communication kernels, at the moment, we assume that:
\(C = A \times B\) where,
\(B\) (weights): sharded column/row-wise across GPUs,
\(A\) (activations): replicated across GPUs, and
\(C\) (activations output): replicated across GPUs.
Currently, there are two implementations:
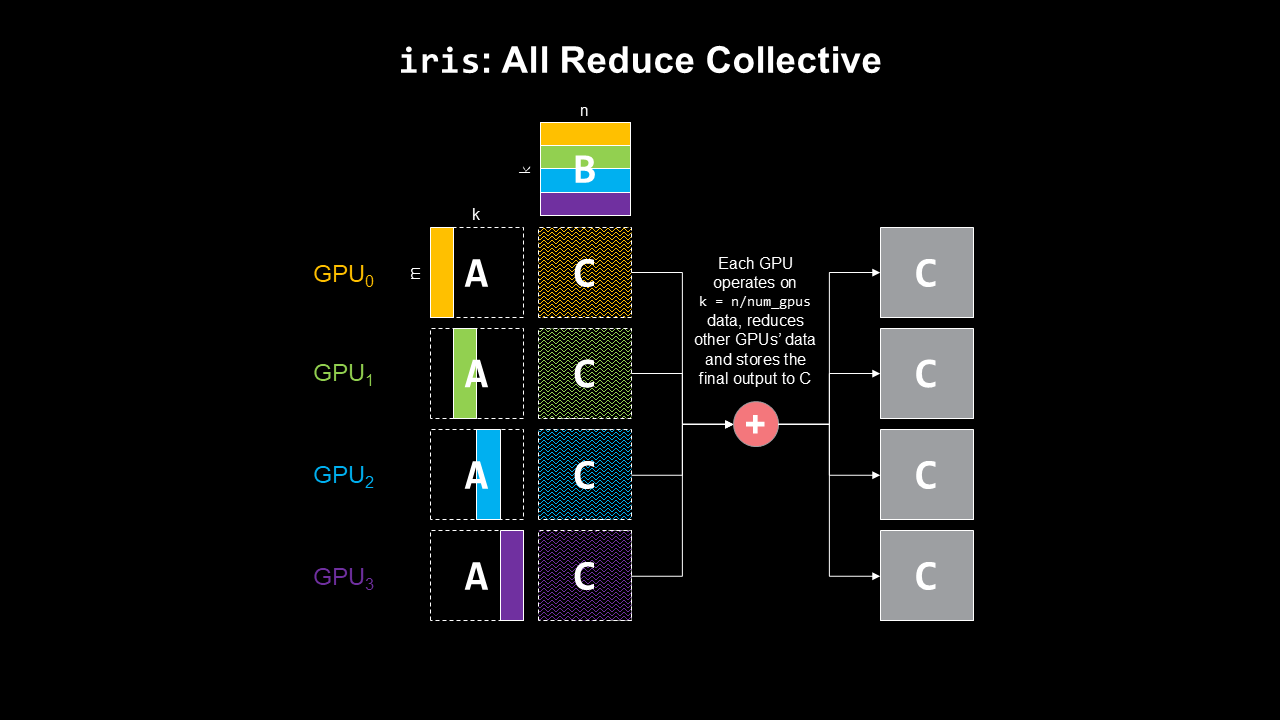
GEMM + All reduce Where \(B\) is partitioned row-wise and hence \(A\) is partitioned column-wise so that we have two tall skinny matrices producing a partial \(C\) with shape of \(M \times N\) and the all reduce kernel reduces the results across all GPUs or ranks (right figure).
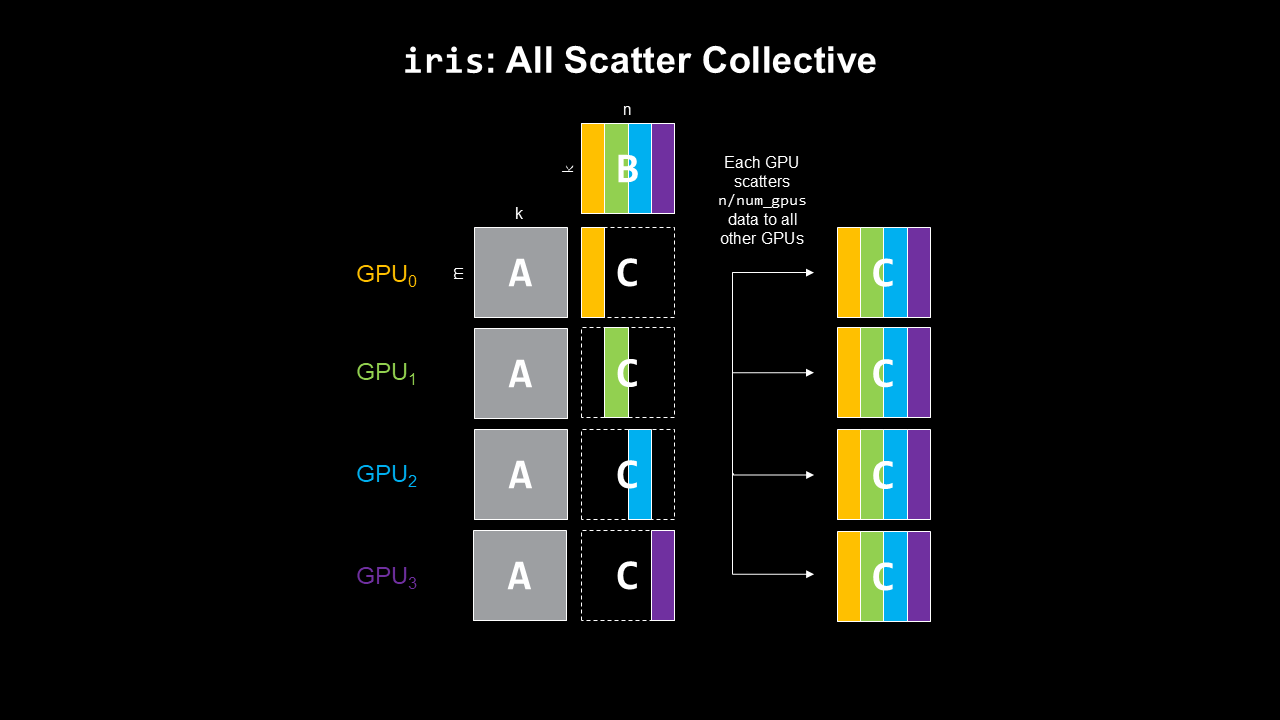
GEMM + All scatter Where \(B\) is partitioned column-wise and hence each rank produces non-overlapping columns in the output \(C\) matrix such that we only need all gather/scatter to broadcast the final result (left figure).